
The Kidney Donation Problem
Some of the most powerful research coming from Operations Researchers originates in the healthcare field where there are some notorious inefficiencies. If you’ve ever had a loved one in need of a life-saving transplant, this emerging research may one day become the difference between life and death for many.
To preface the subject, kidney exchanges aren’t necessarily a new idea, we’ve just never found a way to do them at scale. This project is in inspiration of this PNAS research article.
Humans can live with only one kidney, so many healthy family members will step up and offer one of their’s to a related family member in need. The issue is there must be a compatible blood type match. Without it, we run the risk of rejection. What if a patient doesn’t have a family member with a compatible kidney? This is quite likely — only 25% of siblings are “exact matches”1. Usually these patients are put onto a waiting list for an unrelated donor. Thus we introduce the kidney exchange.
Kidney Exchanges
To solve this predicament, we introduce an exchange system: a patient has a family member willing to give a kidney but unable to due to incompatibility; we find another patient in a similar situation; we match these patient-donor pairs with each other so each donor gives to the other’s patient. The power of this approach is that it increases the supply of compatible kidneys in the system. We implement this at scale through chains and cycles.
Chains
With one Non-directed Donor (NDD) — someone who gives altruistically or posthumously — we can start a chain reaction where that kidney goes to the first patient on our list, and their incompatible family member gives to another patient, and so on:
Cycles
Cycles are similar to chains but started by a donor from a patient-donor pairing rather than an NDD. The cycle completes when a donor gives their kidney to the patient whose donor began the cycle:
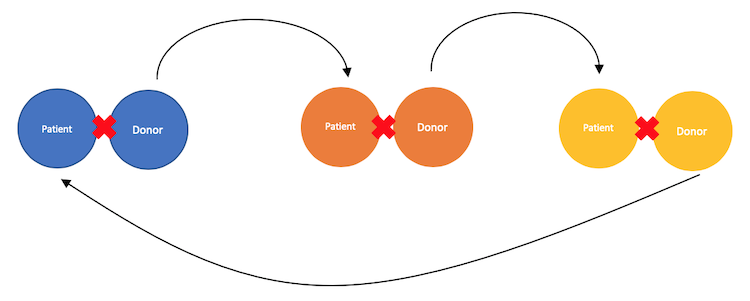
We limit cycles to a maximum length of five. The longer a cycle, the higher the risk that something prevents a pair from completing it. Keeping them short maximizes our feasible region.
The Data
The kidney exchange problem is an integer-programming optimization problem. We are given a dataset of incompatible pairs and a compatibility score for each possible match (the edge weight):
| from | to | w | ndd |
|---|---|---|---|
| 0 | 721 | 38 | 13 |
| 1 | 272 | 5 | 978 |
| 2 | 71 | 44 | 999 |
| 2 | 411 | 58 |
We load this into Julia like this:
dat = readdlm("donor-pool1.csv", ',', '\n', comments=true)
fr = dat[:,1]
to = dat[:,2]
w = dat[:,3]
N = dat[:,4][1:3,] # only 3 NDDs
V = union(fr, to)
E = collect(zip(fr, to))
W = Dict((i,j) => k for (i,j,k) in zip(fr, to, w))The Formulation
For full mathematical detail, see the PNAS article.
Decision Variables
y_ij— binary: 1 if pairi’s donor gives a kidney to pairj’s patientf_in[v]andf_out[v]— flow variables constraining each pair to give/receive at most one kidney
m = Model()
set_optimizer(m, Cbc.Optimizer)
@variable(m, y[(i,j) in E], Bin)
@variable(m, f_in[i in V])
@variable(m, f_out[i in V])Objective Function
Maximize the sum of compatibility weights for all matched pairs:
@objective(m, Max, sum(W[(i,j)] * y[(i,j)] for (i,j) in E))Constraints
Six constraint sets in words:
- Connect
y_ijto the flow variables - If a donor gives a kidney, their patient also receives one (flow in = flow out ≤ 1) for non-compatible pairs
- Each NDD’s flow out ≤ 1 (one kidney to give)
- Prevent cycles longer than 5 (added recursively)
Recursive Algorithm
To constrain cycle length, we solve iteratively: solve → find cycles over length 5 → add constraints to prevent them → resolve. We repeat until no cycles exceed length 5.
The cycle-prevention constraint for a cycle C is:
@constraint(m, sum(y[(i,j)] for i in C, j in C if in((i,j), E)) <= length(C) - 1)Identifying Cycles
After each solve, we capture matched pairs and trace each cycle:
set = []
for (i,j) in E
if value.(y[(i,j)]) > 0
set = union(set, i, j)
end
end
searched = []
U = []
ExtendU = set[rand(1:end)]We walk the solution graph: at each step, find the next pair in the chain/cycle. When ExtendU loops back to U[1], we’ve found a complete cycle. If its length exceeds 5, we add it to Cycle for a constraint in the next solve.
if U[1] == ExtendU
if length(U) > 5
push!(Cycle, U)
cycles_over_five += 1
end
U = []
ExtendU = setdiff(set, searched)[rand(1:end)]
endEnding the Algorithm
We stop when cycles_over_five == 0:
if cycles_over_five == 0
JuMP.optimize!(m)
for (i,j) in E
value.(y[(i,j)]) > 0 && println(i, " to ", j)
end
break
endReadable Output
To make the final solution useful for healthcare professionals, we sort the matches into ordered chains (starting from each NDD) and cycles (the remaining pairs). Each is written to a .csv. See the full Julia source and dataset to run it yourself. Happy programming!